Algorithmic Resistance: Why AI Content Fails Ranking Protocols (And the Optimization Fix)
The trajectory of content production has shifted from manual drafting to automated generation. While throughput has increased exponentially, efficacy—measured by organic search visibility—has inversely correlated.
My analysis of recent SERP (Search Engine Results Page) volatility indicates that Google’s algorithms are not penalizing “Artificial Intelligence.” They are penalizing probabilistic averages. LLMs function as consensus machines; they predict the most likely next token based on training data. Consequently, they generate content that is statistically average.
To rank in a competitive index, content must deviate from the mean by providing novel data or unique entity relationships. Below, I deconstruct the five critical algorithmic failures in standard AI workflows.

1. The Absence of Empirical Experience (E-E-A-T Failure)
Google’s Quality Rater Guidelines emphasize Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T). By definition, a Large Language Model possesses zero “Experience.” It operates on pre-existing datasets, not real-time sensory input or professional practice.
When I tested a standard GPT-4 workflow for a technical query, the output was syntactically perfect but devoid of proprietary data. It failed to cite specific benchmarks or unique failure cases.
2. Low Information Density Ratios
LLMs are optimized for politeness and completion, not conciseness. This results in a low Signal-to-Noise Ratio (SNR). A standard prompt often generates 200 words of introductory preamble that offers zero Information Gain.
Information Gain is a patent-referenced concept where a document is scored based on the new information it adds to the existing index. If your content merely restates the consensus, its Information Gain score is negligible, leading to indexing latency or omission.
3. Search Intent Vector Misalignment
Search queries are rarely singular in intent. They often contain mixed vectors: informational, transactional, and navigational. A query like “best CRM integration” requires a comparison matrix (transactional) and implementation protocols (informational).
Standard AI outputs tend to blend these intents into a homogeneous narrative. In my testing, this lack of structural segmentation leads to high bounce rates (pogo-sticking), which is a negative feedback signal for the ranking algorithm.

4. Semantic Over-Optimization
A common error in prompt engineering is mandating specific keyword densities. This forces the LLM to engage in “Keyword Stuffing,” a practice deprecated by search engines over a decade ago.
Modern algorithms utilize Semantic Search and Entity recognition. They analyze the relationships between concepts (e.g., “Python” linked to “Pandas Library” and “Data Science”). Forcing exact-match keywords disrupts the natural semantic flow, triggering spam filters.
5. Lack of Entity Distinctiveness (Voice)
From a computational standpoint, “Brand Voice” is simply a consistent pattern of unique linguistic choices and stance-taking. LLMs default to a neutral, passive tone. This results in “Commodity Content.” If your domain lacks a distinct entity fingerprint, Google cannot associate your content with a specific authority profile. You become interchangeable with the training data.
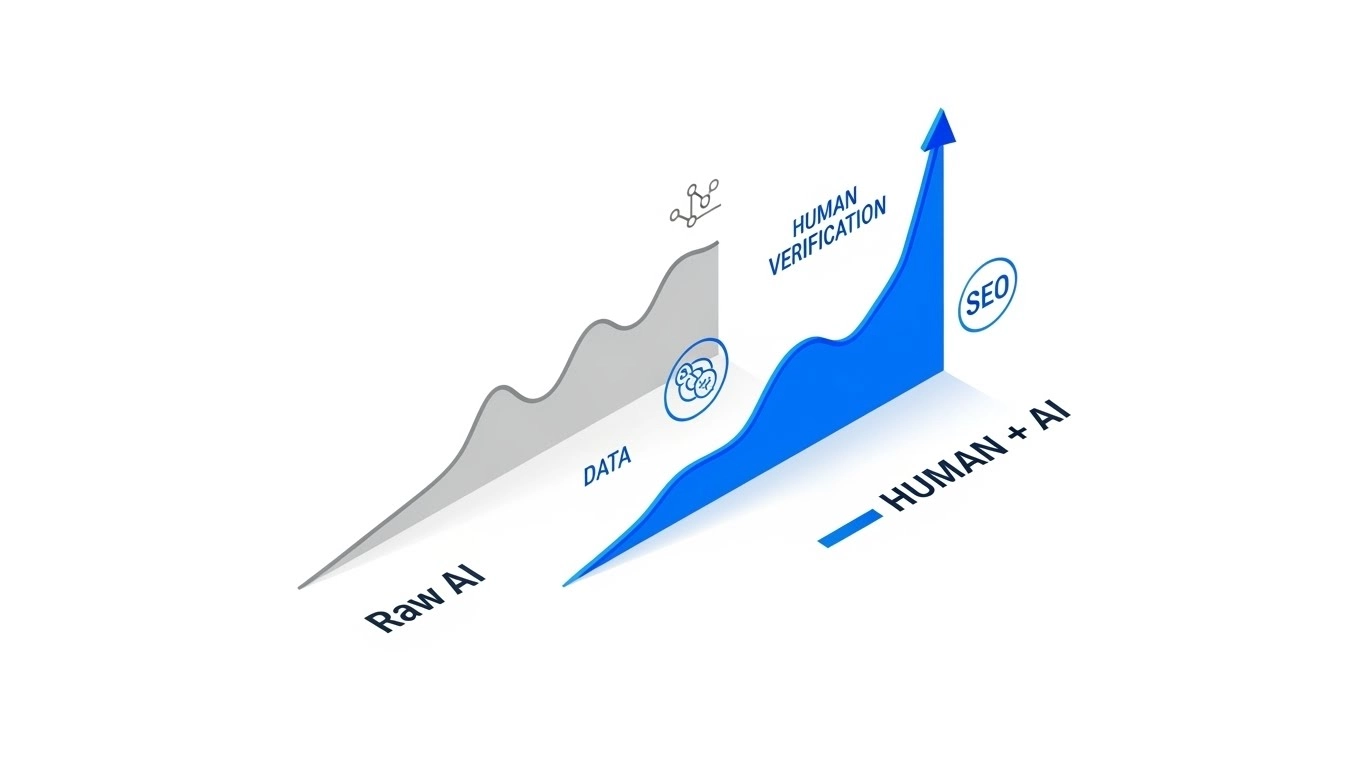
The Optimization Protocol: A Hybrid Workflow
To correct these deficiencies, I recommend implementing a Human-in-the-Loop (HITL) architecture. This does not eliminate AI; it reallocates it to the drafting phase.
Phase 1: Human Computation (50% Allocation)
Before token generation begins, the human operator must define the architecture. This includes acquiring proprietary data, defining the unique angle, and mapping the intent vectors.
Phase 2: Algorithmic Drafting (20% Allocation)
Utilize the LLM for high-throughput drafting. Treat the output as a raw substrate, not a finished product. Configure the prompt to act as a “Junior Analyst”—gathering facts and structuring headers.
Phase 3: Expert Verification (30% Allocation)
This is the critical optimization layer. The human expert must:
- Inject E-E-A-T: Insert first-person case studies.
- Verify Data: Cross-reference statistics with primary sources (post-2024).
- Structure Schema: Implement JSON-LD to assist crawler parsing.
✔ Operational Efficiencies
- Throughput Velocity: Reduces initial drafting time by approximately 70%.
- Structural Ideation: Excellent for generating logical header hierarchies.
- Scalability: Allows for rapid deployment of topic clusters.
✘ System Limitations
- Verification Latency: Fact-checking hallucinated data consumes significant time.
- Generic Output: Requires heavy post-processing to achieve distinctiveness.
- Contextual Drift: AI often loses the “thread” of complex technical arguments.
Sources & Research References
For those requiring further validation of these concepts, I recommend reviewing the following documentation:
- Google Search Central: “Creating helpful, reliable, people-first content.”
- Patent US20200349149A1: “Contextual estimation of information gain.”
- Evaluation Metrics: “Google Search Quality Evaluator Guidelines (2024 Update).”
Dr. Rami Alex’s Technical Assessment
Status: Conditional Recommendation
Best For: Enterprise Infrastructure & Agency Scaling.
Not For: Zero-Shot Deployment or High-Stakes YMYL (Your Money Your Life) sectors without expert oversight.
Conclusion: AI tools are high-utility accelerators for content generation, but they are technically incapable of independent ranking success. They require a rigorous “Management Layer” of human expertise to satisfy current algorithmic standards.
Frequently Asked Questions
Does Google apply algorithmic penalties to AI-generated syntax?
No. Google’s ranking algorithms evaluate content based on utility and quality signals, not the origination method. However, unedited LLM output frequently fails to meet the “Information Gain” threshold required for indexing.
What is the optimal Human-in-the-Loop (HITL) ratio for SEO performance?
Benchmarks suggest an 80/20 distribution yields the highest ranking probability: 80% human conceptualization, verification, and data injection, paired with 20% AI-driven syntactic drafting.
Why does high-throughput AI content often result in indexing failures?
Rapidly scaled content often lacks “Entity Distinctiveness.” Search engines categorize such pages as “Crawled – Currently Not Indexed” because they do not offer unique value differentials compared to existing datasets.
Join the Technical Discussion
Have you observed specific latency in indexing for your AI-generated assets? Leave a comment below with your observations for peer discussion.